

stata15破解版是一款統計管理及圖表繪制軟件,可以為用戶提供了非常多實用的數據統計功能,用戶可以使用這款軟件建造對應的統計圖形,讓數據變得更加直接明了,破解版為用戶提供了注冊工具,感興趣的用戶快來下載看看吧。
軟件介紹
Stata是一款專業級統計軟件,為使用者提供數據分析、數據管理以及繪制專業圖表等三大類功能,用戶可以在軟件中輸入自己得到的數據,然后利用軟件提供的功能對數據進行分析,不同的數據類型可以建造不同的圖表,通過圖表能讓數據對比更加直觀明了。同時軟件還具有很強的程序語言功能,這給用戶提供了一個廣闊的開發應用的天地,真正做到隨心所欲。
Stata在統計分析方面的能力遠遠超過SPSS,在許多方面也超過了SAS!能全面激活計算機的運算能力,運算速度在各個軟件的排名中都遙遙領先。Stata也是采用命令行方式來操作,但使用上遠比SAS簡單,用戶不需要太過復雜的操作,就能進行數據分析。
軟件特色
1、該軟件擁有強大的繪圖功能,可以幫助您分析更多經濟數據
2、可以將實驗數據加載到軟件建立新的統計項目
3、提供了生物數據統計,可以通過圖表展示分析的數據
4、擁有強大的計算功能,實驗結果可以自動計算
5、界面提供了數據編輯器,可以對您添加的數據編輯
6、提供變量顯示窗口,調整函數變量更方便
7、該軟件也提供了專業的圖形分析
8、讓實驗數據更加可視化,讓化學研究數據更清晰
9、在分析市場數據方面也是支持的
10、對于統計數學方面的數據擁有更好的函數方程設置
軟件功能
一、擴展回歸模型
我們稱之為ERMS 擴展回歸模型。四個新的命令適合
1、線性回歸分析,
2、區間回歸包括 tobit模型,
3、概率,
4、有序概率模型
可任意組合成:
1、內生變量
2、非隨機處理任務
3、內源性(Heckman-style)樣本的選擇
這些新的命令讓人驚喜,因為可以在任何一個方程中加入內生變量,包括處理賦值和概率選擇方程。內生變量并不局限于連續性。它們可以是二進制或序數。不管是外生的還是內生的,它們都可以與其他變量相互作用。它們甚至可以互相作用,形成平方項或立方項!
這些新的ERM命令—eregress,eintreg,eprobit, 和eoprobit注定會流行起來,因為他們解決了研究人員的很多問題。首先, 可能有一個內生變量, 因為許多模型都省略了與模型中的變量相關的變量。其次,數據經常被刪剪,而刪剪不是隨機的。ERM 樣本選擇選項允許您對選擇過程進行建模, 并對其進行調整。或者, 如果您正在使用非隨機處理效應模型, 則可以用 ERM處理分配選項。或者, 可以結合處理分配和選擇選項, 其中一些是由于后續的行為而損失的擬合內生處理分配模型。
二、潛在類別分析(LCA)
潛在的均值未被觀測。分類也就是分組。潛在類是數據中未觀測到的組。你可能有關于消費者的數據,并且根據消費者對產品的潛在興趣將他們分成三組。但是,在數據中沒有指定每個消費者所屬組的變量。擬合模型后,你可以
1、使用新的estat lcprob命令估計屬于每一類的消費者比例;
2、使用新的estat lcprob命令估計每個類中Y1、Y2、Y3、Y4的邊際均值(均值就是示例所示的概率);
3、使用新estat lcprob命令來評價適合度;
4、使用現有的predict命令獲取分類成員的預測概率和觀測結果變量的預測值。
三、貝葉斯前綴指令
新的bayes:前綴命令使你能夠適應比以前版本更廣泛的貝葉斯模型。原來也可以擬合貝葉斯線性回歸, 但是現在可以通過輸入文字就可以:在這個模型中, 為變量 id的每個值添加隨機截距。新的bayes:前綴命令在許多Stata評估命令之前工作,并提供超過50種可能性的模型。支持的模型包括多級、面板數據、生存和樣本選擇模型!
新命令支持所有Stata的貝葉斯的功能。你可以從之前的模型參數的分布中選擇,也可以使用之前默認的。當閉合形式解決方案用于Gibbs方法時,可以使用默認的自適應 Metropolis–Hastings 抽樣, 或Gibbs抽樣, 或兩種方法的組合。在bayesmh命令的基礎上可以使用STATA的任何其他功能。可以更改回歸系數的缺省先驗分布,比如,使用prior()選項:
四、線性動態隨機一般均衡(DSGE)模型
DSGEs是經濟學中的一個時間序列模型。它們是傳統預測模型的替代品。兩者都試圖解釋總的經濟現象, 但 DSGEs 允許對來自經濟理論模型的基礎上做這個。建立在經濟理論基礎上的方程很多。這些方程的關鍵特征是, 未來變量的期望值會影響今天的變量。這是區別 DSGEs 與矢量回歸或狀態空間模型的一個特性。另一個特點是, 從理論推導出來的參數通常可以用這個理論來解釋。
在DSGE模型中有三種變量:
1、控制變量和方程,如p沒有沖擊,并且是由方程組決定的。
2、狀態變量 (如 y) 具有隱含的沖擊, 在時間段開始時是預先確定的。
3、沖擊是驅動系統的隨機錯誤。
在任何情況下, 以上dsge 命令可以定義一個模型并擬合。
如果我們有一個關于 beta 和kappa之間關系的理論, 比如它們是相等的, 我們可以用現有的命令test來測試它。
新的 postestimation命令estat policy和estat transition報告策略和轉換矩陣。如果鍵入
顯示將控制變量作為狀態變量的線性函數。如果有五個控制變量和三個狀態變量, 則每個控件將被報告為三個狀態的線性函數。在上面的簡單例子中, 預測 p 的線性函數將顯示為現在的 y 函數。
同時,報告轉換矩陣。而策略矩陣將 p 報告為函數y, 而轉換矩陣則報告 y 如何通過時間演變為p。可以使用Stata的現有預測命令來生成預測。可以使用Stata現有的irf命令來繪制脈沖響應函數。
五、web動態的Markdown文檔
你有沒有聽過Markdown?它是一種創建 html 文檔的流行方式。html 文件是繁瑣的。Markdown簡單直觀,想法很簡單。可以創建一個文件, 其中包含所需的可讀格式的文本, 然后通過它運行一個命令來創建一個HTML文件。
Stata現在支持Markdown, 我們已經添加了標簽 (功能) 到Markdown, 允許包括輸入文件中的Stata命令。你所包含的命令將被運行和顯示, 或者以秘密方式運行, 以及提取輸出的部分供文檔使用。
六、非線性混合效應模型
非線性混合效應模型也被稱為非線性多級模型和非線性層次模型。可以用兩種方式來考慮這些模型。可以把它們看成包含隨機效應的非線性模型。或者可以把它們看成線性混合效應模型, 其中一些或所有的固定和隨機效應都是非線性的。不管哪種方式, 總的誤差分布假設成Gaussian分布。
這些模型在人口藥代動力學, 生物鑒定和研究生物學和農業成長過程中很流行。比如,采用非線性混合效應模型對機體的藥物吸收、地震強度和植物生長進行了模擬。
新的評估命令被命名為 menl。它實現了 popular-in-practice Lindstrom–Bates 算法, 是基于對固定和隨機效應的非線性均值函數進行線性化。支持最大似然和受限最大似然估計方法。
Menl易于使用。可以直接輸入單個方程。大括號{ },用于將要匹配的參數括起來:
除了標準功能外, postestimation特征還包括對隨機效應及其標準誤差的預測,對模型中定義的感興趣參數的預測, 作為其他模型參數和隨機效應的參數、聚類相關矩陣的整體評估等。
中文設置方法
Edit → Preferences → User-interface language
怎么做回歸
生成一個自變量和一個因變量

點擊Statistics|linear model and related|linear regression菜單
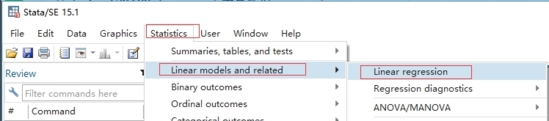
在彈出的regress中設置相關變量,然后再點確定。如下圖:
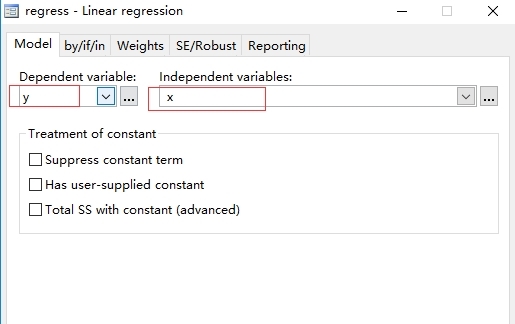
在結果界面中,_cons為.5205279表示回歸截距,說明回歸方程具有統計學意義。R-squared和Adj R-squared分別為0.9905和0.9893,說明回歸方程擬合效果很好
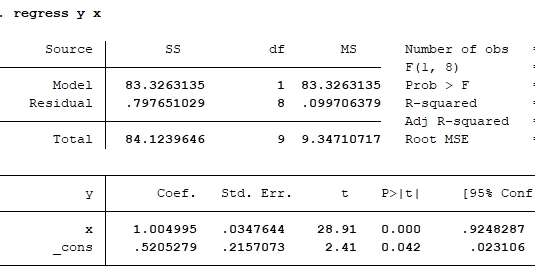
回歸擬合圖。點擊Statistics|linear model and related|Regression diagnostics|Added-variable plot

在彈出的avplot/avplots中,選擇“all variables”,點確定
結果如下圖
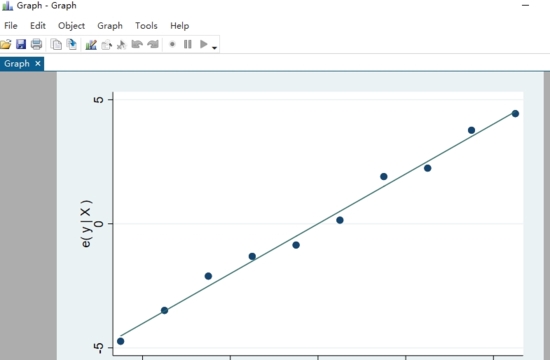
怎么導入數據
數據導入方法一:
直接復制粘貼
絕對簡單明了,不需要任何技術,缺點就在于當數據比較多的時候,拉框選擇還是一件很麻煩的事情,有些數據在excel中可能是顯示小數點后兩位,但實際儲存的并不止這么多。如果是復制粘貼了,可能只粘貼過去小數點后兩位,這樣就損失了一部分精度。最不推薦。
數據導入方法二:
命令:use
1.insheet using filename, [option]
這個命令是專門用來導入像excel之類的以電子表格形式存儲的數據。在導入之前,首先要把excel文件轉存為STATA可以識別的格式。其中我最常用的就是另存為csv逗號分隔符格式。
然后在STATA中使用insheet讀取csv文件,在option中指定為comma告訴STATA你讀取的是csv文件。
這種方法有個不足在于如果你的數據中包含中文而且里面含有逗號時無法識別,解決的辦法是不要用逗號標示分隔符了,在excel中另存為txt(制表符分隔),這樣就不會與逗號相混淆了。然后再在insheet命令中在option里指定是tab,就完事了。
2.infile using filename
這個infile命令分兩類,一種是處理固定格式(fixed format)的txt或raw,另一種是處理自由格式(free format),當然你在用這個命令里還需要定義一個dictionary,這個dictionary是用來描述數據的組織方式的,需要自己根據要導入的數據文件自己編寫代碼,然后嵌套到數據文件txt的前面去,或者是單獨地存為一個dct文件,并且告訴STATA你要導入的數據在保存在哪里。
3.xmluse
這個命令首先要把xls文件另存為xml格式,然后用xmluse命令去讀取,當然在讀取時你也要在option中聲明你的xml文件是excel保存的而不是STATA保存的,這樣就不會弄錯。
如果你的xls文件中如果有漢字的話,STATA讀取后對應的變量會出現亂碼,這一點用insheet就不會有這個問題。
4.odbc
這個命令是專門讀取數據庫文件的,并且支持SQL命令,這樣如果你的數據比較多的話,可以先用SQL語句進行篩選,然后而導入。當然這個命令也能導向excel文件。
數據導入方法三:
點擊“File”→“Open”,找到文件“.dta”,局限比較大,主要是表格類型只支持.dta格式。
數據導入方法四:
點擊“File”→“import”,可以導入xls,txt等其他格式的數據,同樣是對于導入文件的格式有要求。
以上就是小編為你帶來的Stata數據導入方法教程,小編個人比較建議的是調用STATA的內部數據導入命令,到時考慮新手用戶的使用難度,可以選擇更為簡單的導入操作。
怎么導出到EXCEL
首先,在Stata中輸入代碼(ssc install asdoc, replace)安裝外部命令asdoc。

安裝完成后,打開我們的數據,小編這里以Stata自帶的數據auto為例。
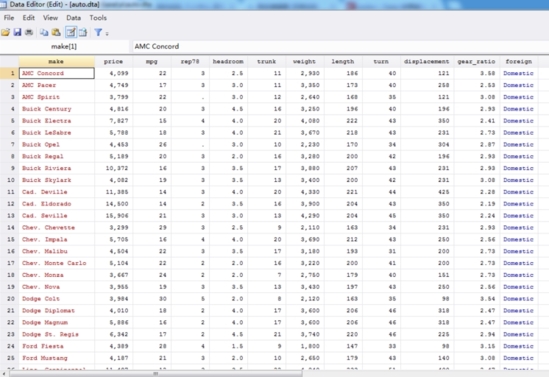
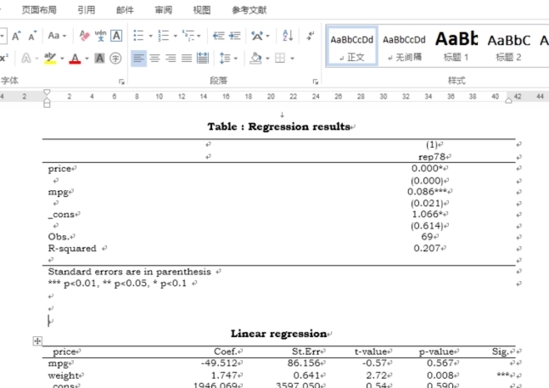
下面,小編做一個mpg和weight變量對price變量的回歸分析,并把結果直接導出到Word里。輸入命令:asdoc reg price mpg weight 。如圖所示,Stata會自動生成一個名為“Myfile.doc”的文件。
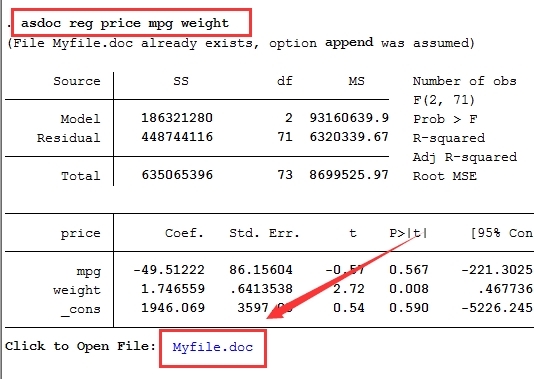
點擊打開Myfile.doc文件,可以看到,我們想要的回歸分析結果已經導出到該Word文檔里了。
使用說明
beta二項式模型
bayesmh是一個回歸命令。 它將結果分布的均值作為預測因子的函數進行建模。 有些情況下,我們沒有任何預測指標,并希望直接對結果分布進行建模。 例如,我們可能想要對我們的結果擬合泊松分布或二項分布。 我們可以通過在可能性()選項中指定bayesmh支持的四種分布之一來做到這一點
多變量回歸
我們考慮一個沒有協變量的簡單多變量正態回歸模型。 我們使用自動。 dta,我們擬合了一個多變量正態分布,用于變量mpg,權重和長度
我們重新調整這些變量以具有大致相等的范圍。 總是推薦均衡模型變量的范圍。 因為這使得模型在計算上更穩定
面板數據和多級模型
雖然MH算法的基礎貝葉斯并不適合擬合貝葉斯多級模型。 您可以使用它來適應沒有太多隨機效應的多級模型。 下面我們考慮兩級隨機截距和隨機系數模型。 兩級隨機效應模型也被稱為面板數據模型

數據分析是在各行各業都非常重要的環節,通過數據分析工具,可以將有用的信息提取出來,對其進行統計和處理,并且可以數據可視化,從而更加便捷的將其展示出來。那么數據分析軟件哪個最好用呢,在這里小編給大家整理了市面上主流的數據分析工具。

















-
本類熱門推薦本類熱門標簽
-
詳情
 Why數學圖像生成工具 綠色版v3.0
2.07MB / 3分
Why數學圖像生成工具 綠色版v3.0
2.07MB / 3分
-
詳情
 金山打字通 綠色版V2.2.0.55
24.9MB / 3分
金山打字通 綠色版V2.2.0.55
24.9MB / 3分
-
詳情
 億圖公式編輯器EdrawMath 官方版v1.0
48.9MB / 3分
億圖公式編輯器EdrawMath 官方版v1.0
48.9MB / 3分
-
詳情
 MathMarkEdit (數學公式編輯器)官方版v1.0
4.52MB / 3分
MathMarkEdit (數學公式編輯器)官方版v1.0
4.52MB / 3分
-
詳情
 algodoo物理沙盒 官方最新版v2.0.0
35.87MB / 3分
algodoo物理沙盒 官方最新版v2.0.0
35.87MB / 3分
-
詳情
 WPS公式編輯器 官方最新版v3.0
9.78MB / 3分
WPS公式編輯器 官方最新版v3.0
9.78MB / 3分
-
詳情
 ChemOffice2018 官方正式版v18.1.0
371.55MB / 3分
ChemOffice2018 官方正式版v18.1.0
371.55MB / 3分
-
詳情





-
2 1stOpt軟件






裝機必備軟件
網友評論