

漢王 PDF OCR是一款文字識別類軟件,軟件支持用戶對PDF文件進行OCR識別,并將識別文本進格式的轉換保存。軟件功能強大,支持上百種字體的識別,并且還支持對表格進行識別。軟件還支持批處理模式,可一次性導入多個文件進行識別處理。
軟件功能
●識別字符
簡體字符集:國標GB2312-80的全部一、二級漢字6800多個。
純英文字符集。
簡繁字集:除了簡體漢字外,還可以混識臺灣繁體字5400多個以及香港繁體字和GBK漢字。
●識別字體種類
能識別宋體、仿宋、楷、黑、魏碑、隸書、圓體、行楷等一百多種字體,并支持多種字體混排。
●識別字號
初號 小六號字體。
●表格識別
可以自動判斷、拆分、識別和還原各種通用型印刷體表格。
軟件特色
漢王OCR文字識別軟件具有識別正確率高,識別速度快的特點。
支持批量處理功能,避免了單頁處理的麻煩。
支持處理灰度、彩色、黑白三種色彩的BMP、TIF、JPG、PDF多種格式的圖像文件;
可識別簡體、繁體和英文三種語言;
具有簡單易用的表格識別功能;
具有TXT、RTF、HTM和XLS多種輸出格式,并有所見即所得的版面還原功能。
安裝方法
1、雙擊從本站下載的安裝包,打開安裝向導,單擊【下一步】。
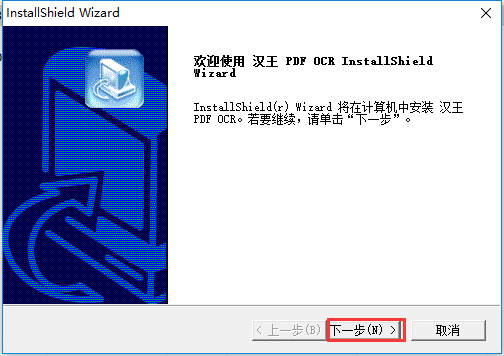
2、同意許可證協議,單擊【是】。
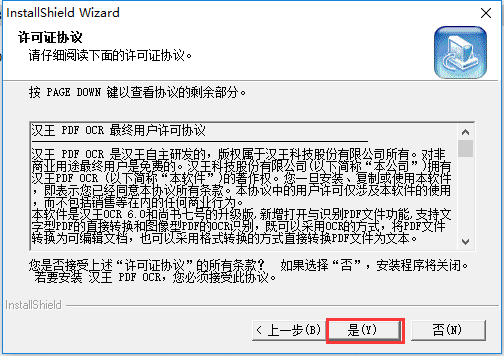
3、單擊【瀏覽】選擇軟件安裝位置,單擊【下一步】。
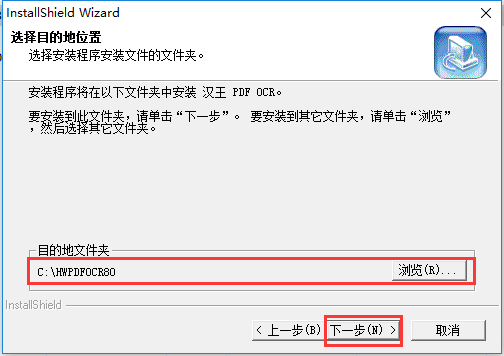
4、耐心等待一下軟件安裝。
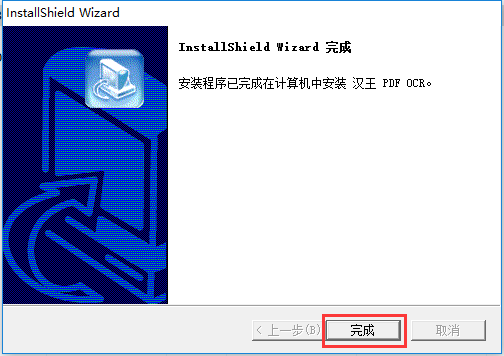
5、安裝完成,單擊【完成】就可以使用軟件了。
使用說明
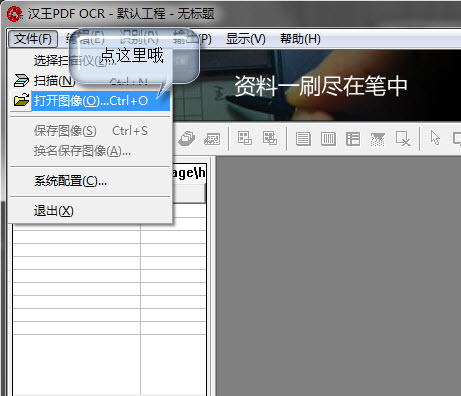
1、在主界面任務欄左上角【文件】選項中選擇打開圖像,快捷鍵Ctrl+O。
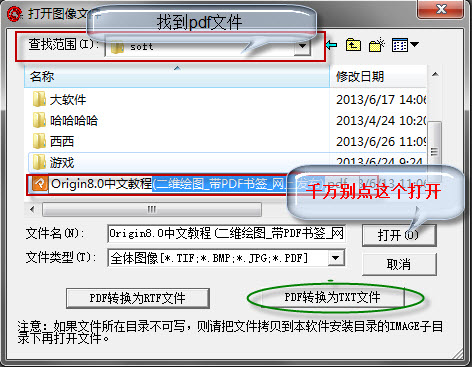
2、查找您需要轉換的pdf文件,注意:不需要點打開,你只需要選中就行,然后點擊【pdf轉換為TXT文件】。
3、選擇你需要轉換的頁面,也就是你pdf文件里邊的內容你需要轉換的部分,默認是全部轉換。然后選擇轉換后txt文版的保存地址,點擊【瀏覽】選擇文件夾。
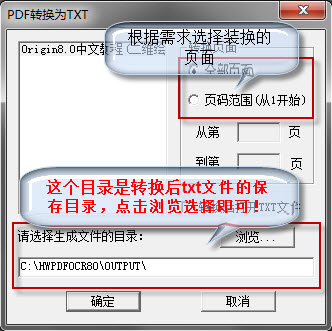
4、轉換完成,時間根據內容的多少來確定。
常見問題
OCR文字識別技術是什么?
光學字符識別(英語:Optical Character Recognition, OCR)是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。OCR的概念是在1929年由德國科學家Tausheck最先提出來,并申請了專利。后來美國科學家Handel也提出了利用技術對文字進行識別的想法。國內最早的OCR商業應用是由中國科學家王慶人教授在南開大學開發出來的,并在美國市場投入商業使用。
標簽: OCR識別












-
本類熱門推薦本類熱門標簽
-
詳情
 Awesome Screenshot(谷歌瀏覽器截圖插件) 官方版v4.3.60
5.68MB / 3分
Awesome Screenshot(谷歌瀏覽器截圖插件) 官方版v4.3.60
5.68MB / 3分
-
詳情
 capture one預設 免費版v1.0
29KB / 3分
capture one預設 免費版v1.0
29KB / 3分
-
詳情
 WebEx Recorder 綠色中文版v2.4
2.44MB / 3分
WebEx Recorder 綠色中文版v2.4
2.44MB / 3分
-
詳情
 Snipaste (截圖軟件)中文版V2.3
22.2MB / 3分
Snipaste (截圖軟件)中文版V2.3
22.2MB / 3分
-
詳情
 ShareX錄屏截圖軟件 漢化中文版V13.1
5.02MB / 3分
ShareX錄屏截圖軟件 漢化中文版V13.1
5.02MB / 3分
-
詳情
 喀秋莎錄屏軟件 官方電腦版v9.1.5
486.6MB / 3分
喀秋莎錄屏軟件 官方電腦版v9.1.5
486.6MB / 3分
-
詳情
 camtasia Recorder 官方中文版v3.0.2
1.37MB / 3分
camtasia Recorder 官方中文版v3.0.2
1.37MB / 3分
-
詳情














裝機必備軟件
網友評論