

爬山虎采集器是最新的頁面采集工具,可以幫助用戶收集信息,再去針對這些內容進行一種可視化的分析,每一步都是非常的簡單并且高效,能大大節省用戶的時間,還在等什么呢?快來使用一下吧。
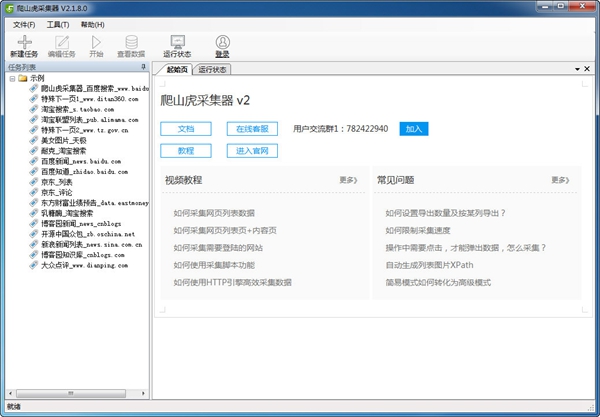
軟件介紹
爬山虎采集器是一款新一代智能化的網頁采集工具,智能分析、可視化界面,一鍵采集無需編程,支持自動生成采集腳本,可以采集互聯網99%的網站。軟件簡單易學,通過智能算法+可視化界面,隨心所欲,抓取自己想到的數據。只要輕松點擊鼠標,就能采集網頁上的數據。
軟件特色
1.獨創高速內核
自研的瀏覽器內核,速度飛快,遠超對手
2.智能識別
對于網頁中的列表、表單結構(多選框下拉列表等)能夠智能識別
3.廣告屏蔽
定制的廣告屏蔽模塊,兼容AdblockPlus語法,可添加自定義規則
4.多種數據導出
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、網站等
5.一鍵提取數據
簡單易學,通過可視化界面,鼠標點擊即可抓取數據
6.快速高效
內置一套高速瀏覽器內核,加上HTTP引擎模式,實現快速采集數據
7.適用各種網站
能夠采集互聯網99%的網站,包括單頁應用Ajax加載等等動態類型網站
軟件功能
1、從任何地方的任何數據的恢復
2、支持超過550種數據格式,包括幾乎所有的圖像文件、多媒體文件、電子郵件、檔案等。
3、支持所有設備的完整數據恢復NTFS,FAT16,FAT32,HFS+,APF,等。
4、先進的算法支持
5、更快的掃描速度由一個內置強大的數據分析引擎驅動。
軟件特點
1、簡單易用的向導驅動界面;
2、PC 或 Mac 上工作完全相同;
3、能夠掃描本地計算機中的所有卷并生成丟失和已刪除文件的目錄樹;
4、搜索匹配文件名條件的丟失和已刪除文件;
5、快速掃描引擎允許快速構建文件列表;
6、簡單明了的文件管理器和典型的保存文件對話框;
7、安全數據恢復:EasyRecovery不會對其正在掃描的驅動器進行寫入操作;
8、可以將數據保存到任何驅動器,包括網絡驅動器、可移動媒體等等;
9、支持 Windows NTFS 的壓縮和加密文件;
10、電子郵件恢復允許用戶查看選定的電子郵件數據庫。將現有的和已刪除的電子郵件都顯示出來,可以用于打印或保存到硬盤。
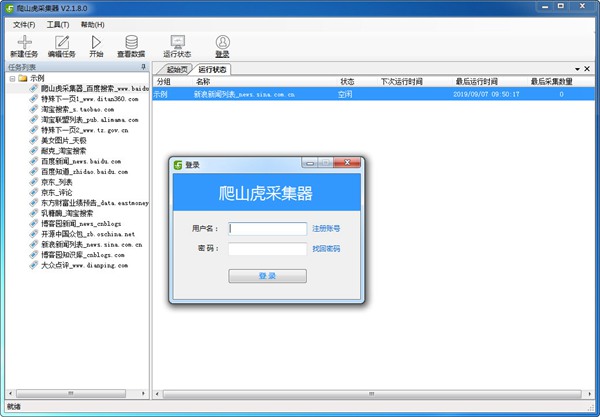
使用方法
用戶下載了爬山虎采集器之后,可能對于這類軟件的基本操作不是很了解,所以往往就會出現使用困難的情況,為了幫助用戶可以更好的知曉爬山虎采集器的使用方法,下面就來講解一下采集任務的新建方法,有需要的用戶快來了解一下吧。
創建第一個采集任務
首先,打開爬山虎采集器,點擊主界面的新建任務按鈕
第一步、選擇起始網址
當你想要采集一個網站數據時,首先需要找到一個展示數據列表的地址。這一步,至關重要,起始網址決定了你采集的數據數量和類型。
以大眾點評為例,我們想要抓取當前城市的美食類的商家信息,包括店名、地址、評分等等信息。
通過瀏覽網站,我們找到所有美食類的商家列表地址
然后在爬山虎采集器V2中新建任務->第一步->輸入網頁地址
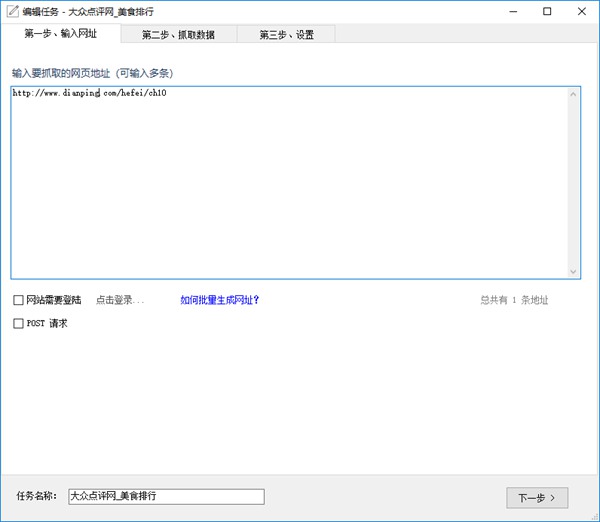
然后點擊下一步。
第二步、抓取數據
進入到第二步后,爬山虎采集器會智能分析網頁,并且從中提取出列表數據。如下圖:
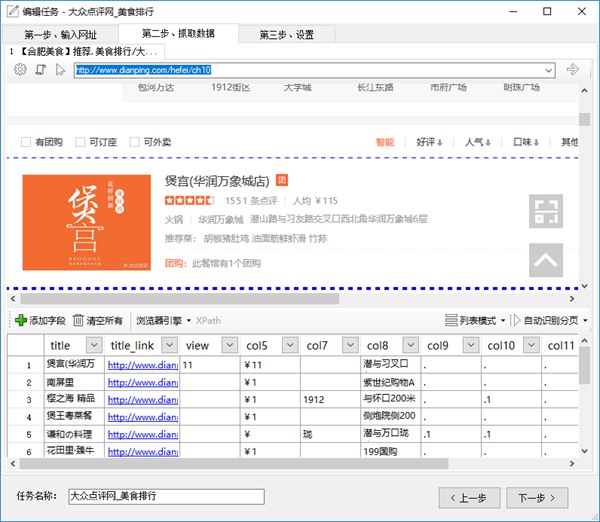
這時,我們對已經分析出的數據進行整理修改,比如刪掉無用的字段。
點擊列的下拉按鈕,選擇刪除字段。
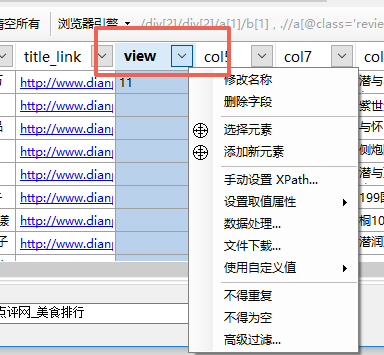
當然還是其他操作,比如修改名稱,數據處理等等。這些我們將在后面的文檔中介紹。
在整理修改字段后,我們來采集處理分頁。
選擇分頁設置->自動識別分頁,程序將會自動定位下一頁元素。
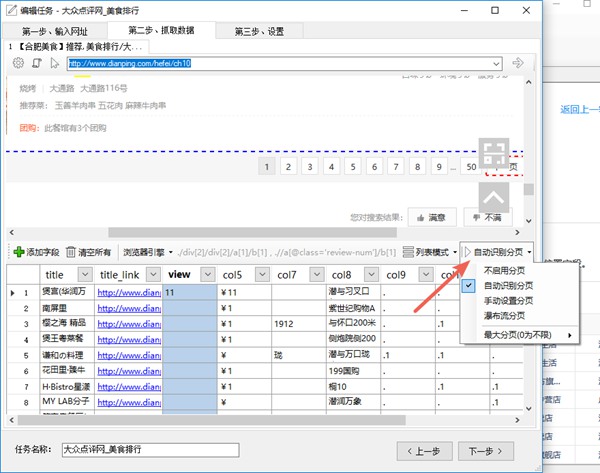
完成之后,點擊下一步。
第三步、設置
這里包括對瀏覽器的配置,比如禁用圖片、禁用JS、禁用Flash、攔截廣告等等操作。可以通過這些配置提高瀏覽器的加載速度。
計劃任務的配置,通過計劃任務,可以設置任務定時自動運行。
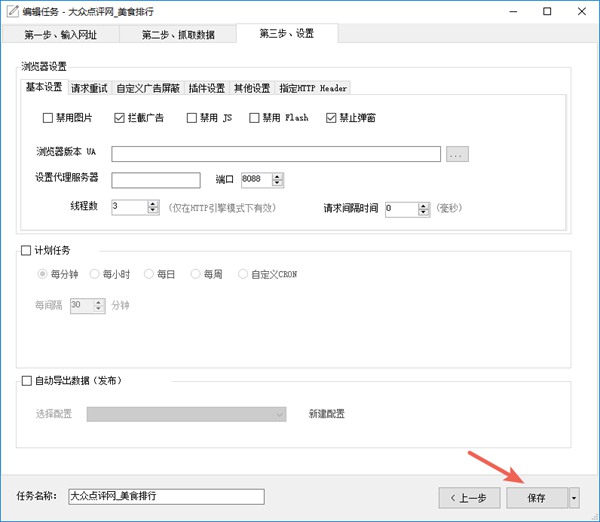
點擊完成,保存任務。
完成,運行任務
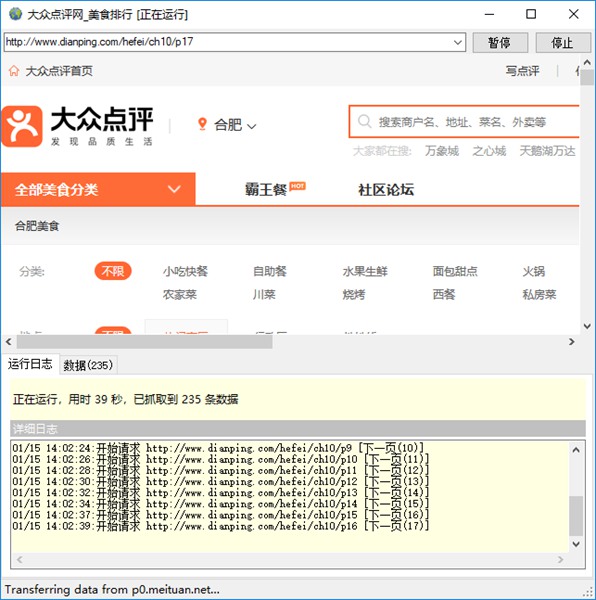
任務創建完成之后,我們選擇剛剛新建的任務,點擊主界面工具欄開始按鈕。
任務運行窗口,任務運行日志,記錄詳細采集日志信息。
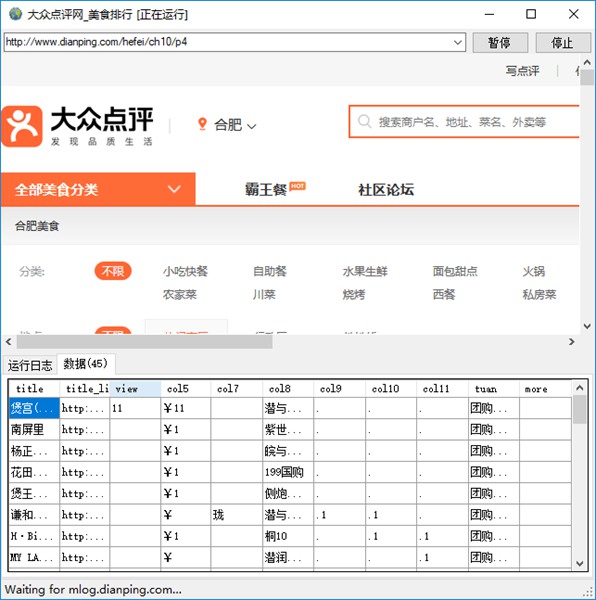
已采集數據窗口,實時顯示已采集的數據
怎么采集圖片
對于用戶來說,單單只是上面的采集基本信息是遠遠不夠的,因為圖片對于用戶來說也是非常重要的一個方面,為了更好的幫助到大家快速的知曉圖片采集的基本步驟,實現圖片快速保存的操作,下面就來分享一下相關的采集方法,來看看吧。
1.點擊添加字段。
2.鼠標點擊網頁中的圖片,程序自動獲取圖片地址。(已有字段,選擇重新選擇元素,然后點擊圖片)
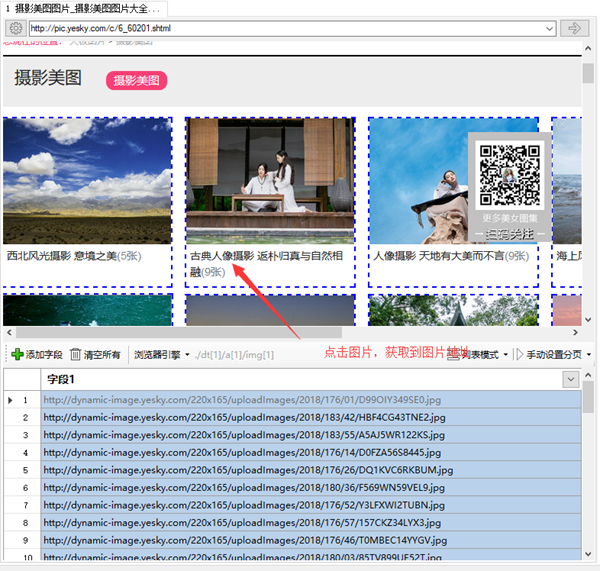
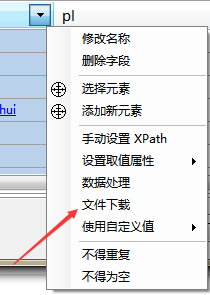
3.選擇要下載的字段,點擊菜單按鈕,選擇文件下載菜單。
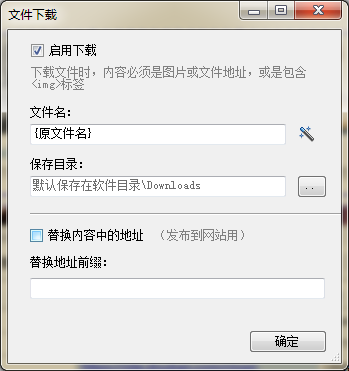
4.設置文件名和圖片的保存路徑。
5.完成。
怎么自定義廣告屏蔽
有的用戶在使用爬山虎采集器的時候,就會發現自己想要去采集的頁面會有非常多的廣告,這些東西都是沒有用處的,會干擾正常的采集操作,增加不必要的存儲空間,所以自定義廣告屏蔽是非常重要的,下面就來分享一下相關屏蔽的方法,快來看看吧。
在爬山虎采集器中,可以通過自定義廣告屏蔽,來加快采集速度。
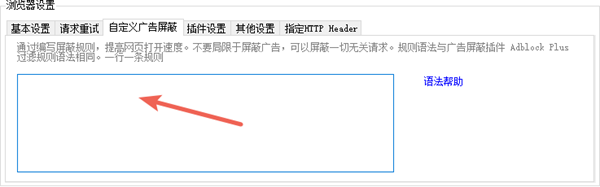
具體語法參考 AdBlock Plus 過濾規則 ,規則為一行一個。
最常用的就是使用通配符,在指定字符前后加星號 *
技巧
一般我們在采集時,注意觀察運行日志,如果出現了如下提示:
頁面加載超過 30 秒限制. 超時請求: Transferring data from ih1.redbubble.net…
我們可以添加規則:*ih1.redbubble.net* ,過濾掉所有包含 ih1.redbubble.net 的請求,這種請求一般是外站圖片、或者js請求。
注意:不要屏蔽你采集的網站主域名,比如你要采集 https://www.baidu.com/s?wd=x ,卻加上規則 *www.baidu.com*,這樣的話,可能就采集不到數據。
常見問題
問:如何過濾列表中的前N個數據?
1.有時我們需要對采集到的列表進行過濾,比如過濾掉第一組數據(在采集表格時,過濾掉表格列名)
2.點擊列表模式菜單中的,設置列表xpath
問:如何抓包獲取Cookie,并且手動設置?
1.首先,使用谷歌瀏覽器打開要采集的網站,并且登陸。
2.然后按下 F12,會出現開發者工具,選擇 Network
3.然后按下F5,刷新下頁面, 選擇其中一個請求。
4.復制完成后,在爬山虎采集器中,編輯任務,進入第三步,指定HTTP Header。
更新日志
新增數據查看- 預覽、編輯完整數據
新增數據查看- 執行 sql 功能
數據處理,新增 自動補全相對URL功能
對單個腳本命令 可設置所有分頁執行(右擊命令行
修改文本框高亮
修復innerText包含style、script問題
修復其他等問題
相關版本









數據分析是在各行各業都非常重要的環節,通過數據分析工具,可以將有用的信息提取出來,對其進行統計和處理,并且可以數據可視化,從而更加便捷的將其展示出來。那么數據分析軟件哪個最好用呢,在這里小編給大家整理了市面上主流的數據分析工具。

















-
本類熱門推薦本類熱門標簽
-
詳情
 神卓互聯內網穿透軟件 官方版v1.85
10.55MB / 3分
神卓互聯內網穿透軟件 官方版v1.85
10.55MB / 3分
-
詳情
 云盤搜索助手 免費版V1.2
6.08MB / 3分
云盤搜索助手 免費版V1.2
6.08MB / 3分
-
詳情
 Wireshark 32位中文版v1.12
22.32MB / 3分
Wireshark 32位中文版v1.12
22.32MB / 3分
-
詳情
 easyconnect(遠程管理軟件) Win10電腦版V6.3.0.1
10MB / 3分
easyconnect(遠程管理軟件) Win10電腦版V6.3.0.1
10MB / 3分
-
詳情
 spoonwep2 (含6個文件)免費版
1.11MB / 3分
spoonwep2 (含6個文件)免費版
1.11MB / 3分
-
詳情
 Boson NetSim 11 免費版v11.7.6487
300MB / 3分
Boson NetSim 11 免費版v11.7.6487
300MB / 3分
-
詳情
 詞達人做題軟件 免費版v1.0
3.6MB / 3分
詞達人做題軟件 免費版v1.0
3.6MB / 3分
-
詳情













裝機必備軟件
網友評論