

Stata16中文破解版是經過修改的版本,安裝包中附帶了永久序列號和激活補丁,讓你可以免費使用這款專業的數據分析軟件。適用于各種領域的研究人員,包括社會科學、生物統計學、健康科學、流行病學、心理學和經濟學。通過它可以為用戶帶來高效的數據分析和數據管理功能,還能將結果生成各式各樣的圖表,將數據可視化。不僅有著傳統的統計方案,還有最新的多類結果與有序結果的logistic回歸,Poisson回歸等功能。

軟件特色
1、線性模型
回歸•審查結果•內生回歸量•自舉,折刀,魯棒和群集穩健方差•工具變量•三階段最小二乘•約束•分位數回歸•GLS•更多
2、小組/縱向數據
具有強大標準誤差的隨機和固定效應•線性混合模型•隨機效應概率•GEE•隨機和固定效應泊松•動態面板數據模型•工具變量•面板單位根測試•更多
3、多級混合效果模型
連續,二元,計數和生存結果•兩級,三級和更高級模型•廣義線性模型•非線性模型•隨機截距•隨機斜率•交叉隨機效應•效果和擬合值的BLUP•分層模型•殘差錯誤結構•DDF調整•支持調查數據•更多
4、二進制,計數和有限的結果
logistic,probit,tobit•泊松和負二項•條件,多項,嵌套,有序,秩序和刻板邏輯•多項概率•零膨脹和左截斷計數模型•選擇模型•邊際效應•更多
5、選擇模型
離散選擇•等級排序備選方案•條件logit•多項式probit•嵌套logit•混合logit•面板數據•特定于案例和特定于備選方案的預測器•解釋結果預期概率,協變量效應,跨備選方案的比較•更多
6、擴展回歸模型(ERM)
內源性協變量•樣本選擇•非隨機處理•小組數據•單獨或組合出現問題•連續,區間刪失,二元和有序結果•更多
7、廣義線性模型(GLM)
十個鏈接函數•用戶定義的鏈接•七個分布•ML和IRLS估計•九個方差估計•七個殘差•更多
8、有限混合模型(FMM)
fmm:17個估算器的前綴•單個估算器的混合•混合多個估算器或分布的混合•連續,二元,計數,序數,分類,刪失,截斷和生存結果•更多
9、空間自回歸模型
因變量,自變量和自回歸誤差的空間滯后•面板數據中的固定和隨機效應•內生協變量•分析溢出效應•更多
10、ANOVA / MANOVA
平衡和不平衡設計•階乘,嵌套和混合設計•重復測量•邊際均值•對比•更多
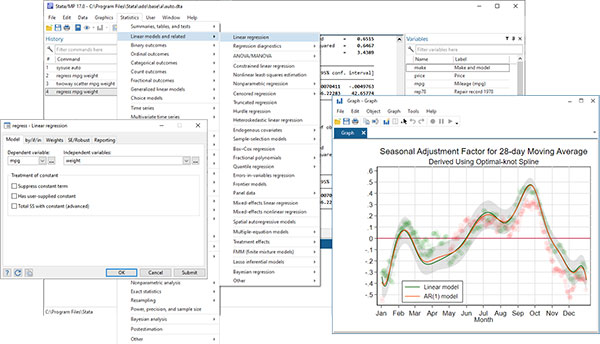
安裝方法
1、在本站下載并解壓,得到如下文件,雙擊運行“SetupStata16.exe”安裝原程序

2、進入安裝向導,點擊下一步
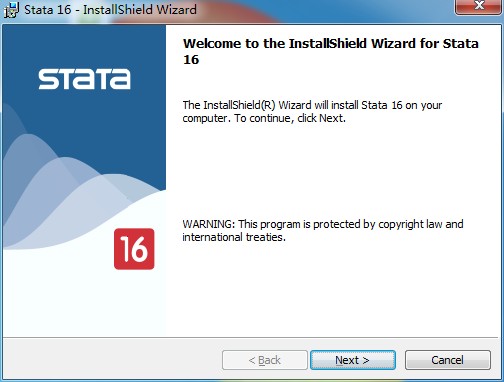
3、勾選我同意許可協議,如圖所示
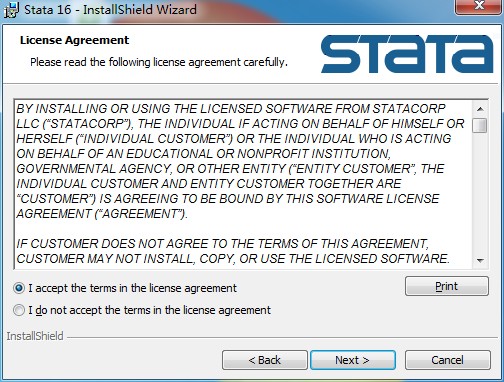
4、設置用戶賬戶信息
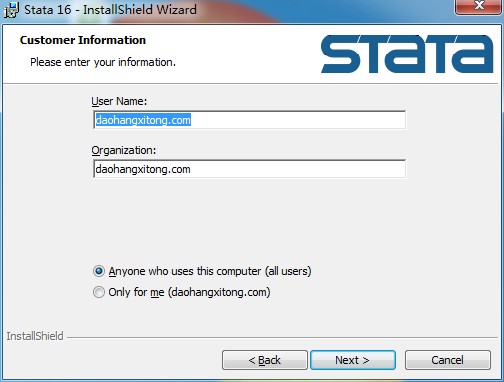
5、安裝時請選擇安裝StataMP
6、選擇軟件安裝目錄
7、核對安裝信息,確認無誤后即可點擊【Install】按鈕繼續
8、軟件安裝完成,退出向導
8、安裝完成后復制 Crack 文件夾里的 STATA.LIC 和 StataMP-64.exe 到安裝目錄覆蓋
默認路徑為:C:\Program Files\Stata16
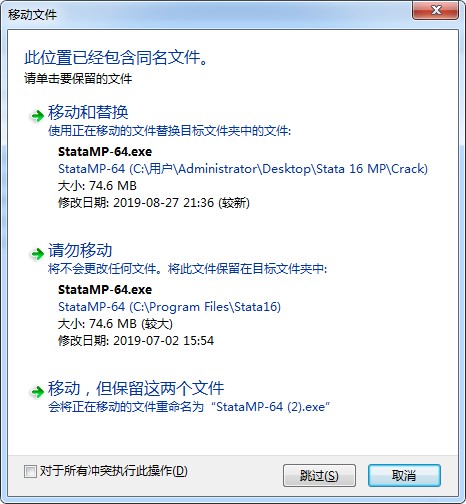
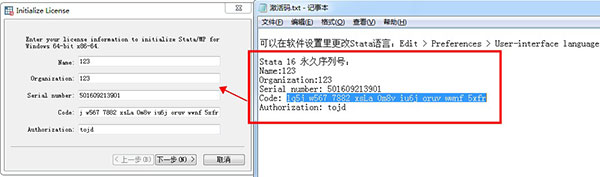
9、啟動軟件,將激活碼.txt中文的文件復制到注冊界面
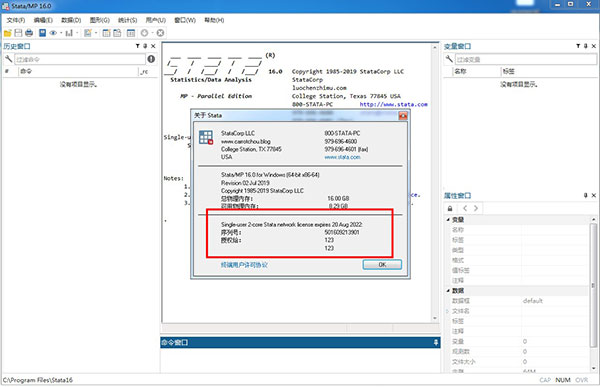
10、正常進入軟件,查看信息,顯示到2022年,表示Stata 16中文破解版安裝完畢,請放心使用
怎么撤銷前一步命令
我們在使用Stata一邊寫命令一邊運行的時候,偶然會出現命令寫錯,但是依舊運行了出來,就會產生一些錯誤的數據,那么要如何撤銷上一步的命令呢,一起來看看解決的方法。
1、Stata目前是無法撤銷上一步命令和運行結果的。
2、但是針對這個情況我們還是有解決方法的:
①事先使用preserve預存數據,運行命令之后使用restore恢復數據;
②運行命令之后,clear清空內存,然后再調入數據。
如何合并數據
在使用Stata的過程中,我們經常會遇到數據很多,許多對其進行合并的情況,不少用戶不清楚要如何合并數據,下面就給大家帶來了橫向合并和縱向合并的方法。
一、數據的橫向合并
1、數據的橫向合并是橫向拆分的逆操作,但是其要比拆分復雜。對于時間序列資料而言,要保證同一時點的兩個變量的觀察值對接到同一行;而對于截面個體資料而言,要保證同一個人的年齡數據與該人的收入數據在同一行。
2、而對于面板數據資料,則需數據中有兩個變量能夠唯一標示每一行觀察值,以保證 A 數據文件中的 “dy2016” 與 B 數據文件中的 “dy2016” 處于同一行。合并所使用的命令語句為 merge,具體語句如下所示:
merge [varlist] using filename [filename ...] [, options]
3、其中,merge 為合并的命令語句,[varlist] 代表用以合并的變量,using filename 指的是與原文件進行合并的文件。options 具體選項如下:
keep(varlist):只保留 filename 中特定的變量;
_merge(newvar):合并之后生成的新變量,默認名稱為 _merge;
nolabel:不要復制 filename 中所定義的標簽;
nonotes:不要復制 filename 中所定義的注釋;
update:用 filename 中的數據代替內存中的缺失值;
replace:用 filename 中的數據代替內存中中的非缺失值;
nokeep:刪除數據庫中不能匹配的觀測值;
nosummary:刪除 summary 變量;
unique:匹配變量在原文件與合并文件中都是唯一的;
uniqmaster:匹配變量在原文件中必須是唯一的;
uniqusing:匹配變量在用以合并文件中必須是唯一的;
sort:合并前進行排序。
4、利用數據文件 waterinput 和 wateroutput 實現數據的橫向合并,匹配變量為 year,生成新的數據文件命名為 waternew。
二、數據的縱向合并
1、數據的縱向合并為數據縱向拆分的逆操作,使用的主要命令為 append 命令,具體語句如下:
append using filename [, options]
2、在這個命令語句中,append 是進行縱向合并的命令語句,using filename 是進行縱向合并的文件路徑,[, options] 的內容與 merge 相似,但更為簡化。
3、例如,利用數據文件 auto_domestic.dta 和 auto_foreign 實現數據的縱向合并,生成的數據文件命名為 autonew.dta。
怎么定義時間變量
Stata和Excel的數據雖然來相互導入和導出,但是他們之間的變量設置方法是不一樣的,不少用戶經常出現錯誤的提示,一起來看看具體的操作方法。
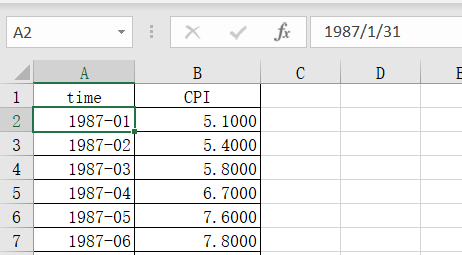
1、例如這里有一個CPI同比的月度數據,如下圖EXCEL表所示。用EXCEL可以很方便的做圖等,但是我們現在把數據導入Stata之后,會發現時間列是紅色,也就是說,在Stata看來,這列數據是文本格式,那么對時間作圖等等,都是失敗的。
Stata會報錯如下。
line cpi time
string variables not allowed in varlist;
time is a string variable

2、因此我們如果要在Stata中處理時間變量,第一件事就是要把文本格式的時間,轉換成Stata可以識別的格式。轉換的命令叫做date,其格式是:
date(s1,s2),其中s1是文本格式的時間變量,s2是文本格式時間的年月日的排列次序
3、現在我們運行命令:
gen timen = date(time, “YM”)
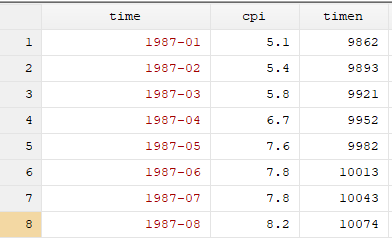
4、可以看到,新生成的時間變量timen,是一串整數,這是什么意思呢?第一,date這個命令識別的文本格式,是日度格式,如果原始數據是月份,比如1987-01,那么Stata會自動補充上日,默認為每個月的1號,即1987-01-01;第二,1987-01-01對應的9862,是指距離1960年1月1日的天數。
相關版本


數據分析是在各行各業都非常重要的環節,通過數據分析工具,可以將有用的信息提取出來,對其進行統計和處理,并且可以數據可視化,從而更加便捷的將其展示出來。那么數據分析軟件哪個最好用呢,在這里小編給大家整理了市面上主流的數據分析工具。




















-
本類熱門推薦本類熱門標簽
-
詳情
 project 2013 免費中文版(附激活密鑰)
1KB / 3分
project 2013 免費中文版(附激活密鑰)
1KB / 3分
-
詳情
 蘇打辦公 最新版v2.0.0.1441
16.7MB / 3分
蘇打辦公 最新版v2.0.0.1441
16.7MB / 3分
-
詳情
 ProjeQtOr (項目管理軟件)最新版v9.0.2
50.67MB / 3分
ProjeQtOr (項目管理軟件)最新版v9.0.2
50.67MB / 3分
-
詳情
 DzzOffice開源版 最新源碼版v2.02.1
19.22MB / 3分
DzzOffice開源版 最新源碼版v2.02.1
19.22MB / 3分
-
詳情
 Draw.io Desktop流程圖繪制軟件 便攜免安裝版v13.9.5
70.52MB / 3分
Draw.io Desktop流程圖繪制軟件 便攜免安裝版v13.9.5
70.52MB / 3分
-
詳情
 project2016 官方版
540MB / 3分
project2016 官方版
540MB / 3分
-
詳情
 華望云會議視頻軟件 官方版v3.6.1.8
22.76MB / 3分
華望云會議視頻軟件 官方版v3.6.1.8
22.76MB / 3分
-
詳情
-
8 網會視頻會議助手














裝機必備軟件
網友評論