



mindspore掌中寶是依靠功能強大的智能計算框架,不僅在學術上有著巨大的作用,也能滿足工業方面的性能需求,支持照片檢測、代碼分享、場景識別等諸多功能,對于開發者而言此軟件也極為實用,極大提升了編程的效率,讓用戶可在短時間內完成調試及部署等操作。
軟件功能
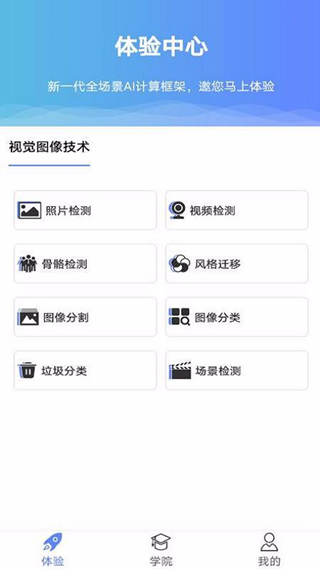
1、識別垃圾類別,通過垃圾分類功能可以利用相機檢測識別垃圾的類別;
2、檢測場景范圍狀況,使用場景檢測功能掃描識別當前的場景并獲取參數信息;
3、照片經檢測識別,點擊照片檢測即可馬上打開照片并查看其中的各種檢測元素;
4、給該軟件點贊,能在我的主頁選擇點贊功能并根據自己的使用體驗給軟件點贊;
5、將軟件分享給自己的好友,選擇并點擊一鍵分享功能即可將軟件分享;
6、查詢代碼資源,進入到官方代碼倉中就能從中查找需要的代碼內容資源;

軟件特色
極致性能
高效的內核算法和匯編級優化,支持CPU、GPU、NPU異構調度,最大化發揮硬件算力,最小化推理時延和功耗。
輕量化
提供超輕量的解決方案,支持模型量化壓縮,模型更小跑得更快,使能模型極限環境下的部署執行。
全場景支持
支持iOS、Android等手機操作系統以及LiteOS嵌入式操作系統,支持手機、大屏、平板、IoT等各種智能設備上的應用。
高效部署
支持MindSpore/TensorFlow Lite/Caffe/Onnx模型,提供模型壓縮、數據處理等能力,統一訓練和推理IR,方便用戶快速部署。
快速入門
通過一個實際樣例實現手寫數字的識別,帶領大家體驗MindSpore基礎的功能,一般來說,完成整個樣例實踐會持續20~30分鐘。
情感分析
構建一個自然語言處理的模型,通過文本分析和推理實現情感分析,完成對文本的情感分類。
圖像分類
結合CIFAR-10數據集,講解MindSpore如何處理圖像分類任務。
識別貓狗APP
在PC上對預訓練模型進行重訓,在手機終端完成推理和部署,1小時內體驗MindSpore端邊云全場景開發流程。
適用場景
圖像分類
您可以使用預制圖像分類模型,識別攝像頭輸入幀中的物體。
目標檢測
您可以使用預置目標檢測模型,檢測標識攝像頭輸入幀中的對象并添加標簽,并用邊框標識出來。
圖像分割
圖像分割可用于檢測目標在圖片中的位置或者圖片中某一像素是輸入何種對象的。
mindspore掌中寶軟件優勢
1、圖像分割:可用于檢測目標在圖片中的位置,或判斷圖片中某一像素對應的對象類型。
2、圖像分類:提供預制圖像分類模型,能識別攝像頭輸入幀中包含的物體,實現快速識別。
3、目標檢測:配備預置目標檢測模型,可檢測并標識攝像頭輸入幀中的對象,添加標簽且用邊框標注。
軟件內容
1、極致性能:采用高效內核算法與匯編級優化,支持 CPU、GPU、NPU 異構調度,最大化硬件算力,最小化推理時延與功耗。
2、全場景支持:兼容 iOS、Android 等手機系統及 LiteOS 嵌入式系統,適配手機、大屏、平板、IoT 等各類智能設備的智能應用。
3、輕量化:提供超輕量解決方案,支持模型量化壓縮,讓模型體積更小、運行更快,實現智能模型在極限環境下的部署執行。
軟件特點
1、簡單的開發體驗:助力開發者實現網絡自動切分,僅需串行表達即可完成并行訓練,降低開發門檻,簡化開發流程。
2、靈活的調試模式:具備訓練過程靜態執行與動態調試能力,開發者變更一行代碼即可切換模式,快速在線定位問題。
3、充分發揮硬件潛能:最佳匹配昇騰處理器,最大程度釋放硬件能力,幫助開發者縮短訓練時間,提升推理性能。
4、全場景快速部署:支持云、邊緣及手機端的快速部署,實現更優資源利用與隱私保護,讓開發者專注于智能應用創作。
特別說明
軟件信息
- 包名:com.mindspore.himindspore
- MD5:8EF306168B5F6588A082C9E8612B1209

 編程獅
編程獅
 探月校園版
探月校園版
 核桃編程(學生端)
核桃編程(學生端)
 QPython
QPython
 QPython OH
QPython OH
 Anycodes在線編程app
Anycodes在線編程app
 Dxapp
Dxapp












 高校邦APP
高校邦APP
 WPS Office精簡版
WPS Office精簡版
 樂樂作文
樂樂作文
 書小童
書小童
 好分數家長版
好分數家長版
 TeamViewer 15
TeamViewer 15
 小拉出行司機端
小拉出行司機端
 象棋微學堂
象棋微學堂
 ClassIn
ClassIn